Multi Agent Systems - A Review
- Apr 13
- 7 min read
Multi-Agent Large Language Models (MA-LLMs) — essentially, using groups of AI models (like GPT or Claude) to "talk" and "debate" with each other to solve problems, rather than relying on just one.
Here are some key ideas:
"Two Heads Are Better Than One"
There are recent studies that demonstrate when multiple AI agents work together, they usually perform better than a single AI. By debating, giving each other feedback, and looking at a problem from different perspectives, they are more likely to find the correct answer for complex tasks like math or software coding or many other reasoning tasks found in businesses.
How They Reach a Decision
Since the agents might disagree, there are three main ways they wrap up a conversation and pick an answer:
Majority Voting: The agents all give an answer, and the most common one wins.
A Judge: A separate AI agent acts as a "referee" to listen to the debate and make the final call.
Consensus: The agents talk until they all agree on one specific solution.
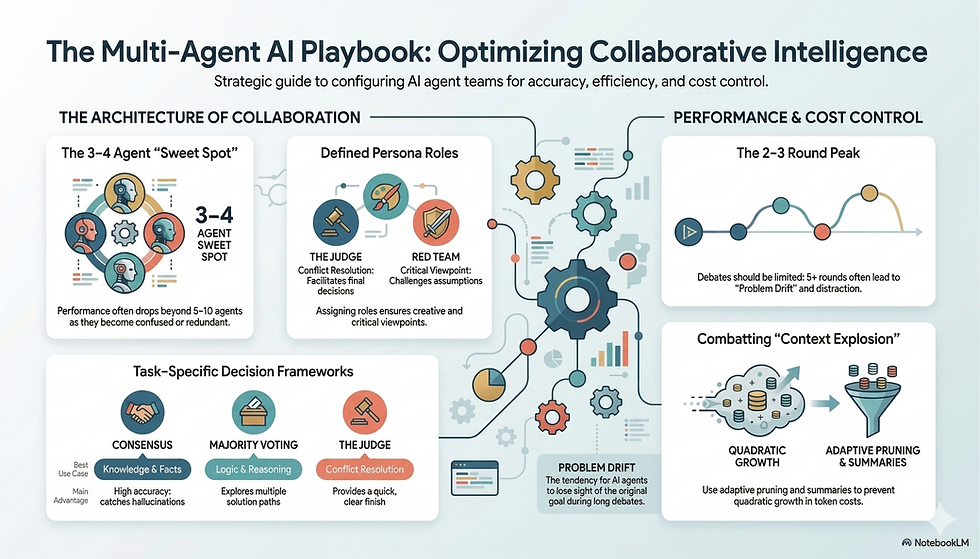
The "Sweet Spot" for Team Size
You might think adding more AI agents always makes the team smarter, but that isn't the case:
The Magic Number: Many studies found that 3 to 4 agents is the "sweet spot".
Too Many Cooks: If you have more than 5–10 agents, the performance often drops because they get confused, repeat themselves, or provide too much conflicting information for the system to handle.
The Limits of Debating
One must be aware of "Problem Drift". If the AI agents debate for too many rounds, they sometimes get distracted and wander away from the original question, which actually makes their final answer worse. Most systems find the best results after just 2 or 3 rounds of talking. (More on this later)
The "Context Explosion" Problem
A major downside to these multi-agent systems is the cost and "brain power" required. Every time an agent speaks, it uses "tokens" (units of text). In large groups, the amount of text grows so fast (quadratically) that it can overwhelm the AI's memory and become very expensive to run.
Roles of each Agent
In multi-agent systems, developers don't just "let AI talk"—they often give each agent a specific persona or job description to ensure the debate is productive.
Here are the most common roles agents play:
The Naive Debater: This is the "idea generator." Their job is to simply engage in the debate and suggest potential solutions or thoughts without overthinking the process (The Beer Bicep).
The Judge: As the name suggests, this agent acts as the referee. It listens to the other agents' arguments and makes the final decision on which answer is the best (The Arnab Goswami).
The "Red Team" (Critic/Verifier): This agent is the "Devil’s Advocate." Their sole purpose is to find flaws, errors, or logic gaps in the other agents' suggestions to ensure the final answer is actually correct (The Leader of the opposition).
The Management Team (Secretary/Moderator): These agents don't solve the problem themselves. Instead, they summarize the discussion, keep the conversation on track, or act as an "orchestrator" to manage who speaks when (The speaker of the Lok Sabha).
Specialized Professional Roles: For technical tasks like building software, agents are given high-level professional profiles like CEO, CTO, Programmer, or Tester to simulate a real-world work environment.
By assigning these roles, the system ensures that different "viewpoints" (like being critical vs. being creative) are always represented in the conversation
Decision Making Frameworks
There is no single "best" method. Instead, the right choice depends entirely on the type of task the AI is trying to solve.
Here is how the main methods compare:
1. Consensus: Best for Facts & Knowledge
How it works: Agents talk until they all agree.
Why it's good: It acts like a rigorous fact-checker. Because multiple agents must agree on a statement before it is finalized, it is very good at catching small errors or "hallucinations".
The downside: It can be time-consuming and may lead to "groupthink," where agents just agree with the loudest or first opinion instead of thinking for themselves.
2. Majority Voting: Best for Puzzles & Logic
How it works: Each agent gives an answer, and the most popular one is chosen.
Why it's good: It is excellent for reasoning tasks (like complex logic puzzles or math). It allows different agents to explore different "paths" to a solution. Even if some go the wrong way, the majority usually finds the right path.
The downside: It can be "tricked" if the wrong answer is very common or if the agents all share the same bias.
3. The Judge: Best for Resolving Deadlocks
How it works: A separate AI agent listens to the debate and picks the winner.
Why it's good: It provides a clear way to end the conversation quickly, especially if the other agents are stuck in an infinite loop or can't agree.
The downside: The final answer is only as good as the judge. If the judge has a "positional bias" (e.g., it always favors the first agent who spoke), it can make the wrong call even if the other agents were right.
Summary Table
Method | Best Use Case | Main Advantage | Main Risk |
Consensus | Knowledge/Facts | High accuracy; catches errors | Slow; "Groupthink" |
Voting | Logic/Reasoning | Explores many ideas | Can follow "popular" errors |
Judge | Conflict Resolution | Quick, clear finish | Subject to Judge's own bias |
Problem Drift
In simple terms, Problem Drift is like a group of people in a meeting who start off talking about a project but end up debating what to order for lunch—they completely lose sight of the original goal.
Here is why this happens to AI:
1. The "Telephone Game" Effect
As the agents talk back and forth over many rounds, they start responding more to what the last agent said rather than the original question. Small misunderstandings in round one get magnified by round five, leading the whole group down a "rabbit hole" of incorrect information.
2. Cognitive Overload (Context Explosion)
Every time an agent speaks, that text is added to the "memory" of the conversation. Eventually, the conversation becomes so long and cluttered that the AI agents have trouble "remembering" the most important parts of the original task.
3. Degeneration-of-Thought
This is a specific type of drift where an AI becomes "stubborn." Once an agent decides on an answer (even if it's wrong), it stops looking for new ideas and just spends the rest of the debate trying to defend its mistake. This prevents the group from ever finding the right solution, no matter how long they talk.
The Result?
The research shows that while a little bit of talking helps, too much of it is actually harmful:
1–2 Rounds: Usually the best for simple tasks.
3–4 Rounds: The "peak" for difficult problems.
5+ Rounds: Performance often starts to drop as the agents get "confused" or distracted.
To keep these AI "meetings" from becoming too long, expensive, and confusing, there several clever "pruning" strategies that researchers use to keep the agents focused:
1. The "Adaptive Break" (Knowing When to Quit)
Instead of forcing the AI to talk for a set number of rounds, the system monitors the debate. If the agents reach a consensus (everyone agrees) or if they start repeating themselves, the system triggers an "early exit" to stop the conversation immediately. This prevents Problem Drift before it starts.
2. Group Discussion (Dividing and Conquering)
A method called GroupDebate divides a large team of agents into smaller "subgroups."
Each small group debates the problem internally and writes a short summary of their conclusion.
Only these summaries are shared with the other groups.
This drastically cuts down the amount of text (tokens) the AI has to "read," saving both memory and money.
3. Agent Pruning (Firing the "Weak Links")
Not every AI agent is equally helpful. Some systems use an "Agent Importance Score" to rank how much value each agent adds to the conversation. If an agent is consistently wrong or just repeating what others say, the system deactivates them mid-debate to keep the "room" quiet and focused.
4. Memory Management
Instead of the AI reading the entire chat history every single time someone speaks, researchers are testing Short-Term and Long-Term memory systems. This allows the AI to "remember" the most important goals and facts without getting bogged down by every single word said in the previous rounds.
Summary of Benefits:
Saves Money: Less text means lower costs for using models.
Stays Sharp: Removing "noise" helps the AI stay focused on the original question.
Scales Up: These tricks allow researchers to run systems with hundreds or even thousands of agents without the system crashing
The Future Roadmap
Here are the four big goals researchers are chasing:
1. "Real-World" Job Training
Currently, most AI agents are given a simple text description of their role (like "You are a programmer"). We need Data-Derived Profiles. This means training AI agents on real-world data from specific experts—like actual surgeons, engineers, or lawyers—so they bring deeper, more realistic expertise to the debate rather than just "acting" the part.
2. Massive "Mega-Teams"
While current research says 3–4 agents is the "sweet spot," some new frameworks are testing collaboration between over a thousand agents. The goal is to see if we can orchestrate "digital cities" of AI to tackle massive projects, such as designing an entire operating system or solving global logistics problems, which a small team simply couldn't handle.
3. Fighting "Group Bias"
Just like a group of humans can fall victim to "peer pressure" or "echo chambers," AI teams can develop Group-Level Biases. Future research is focusing on how to program "independent thinkers" into the system so the AI doesn't just agree with the majority because it's the "easiest" path.
4. Cost-Effectiveness Formulas
Right now, using multiple AI agents is very expensive because they talk a lot. Some researchers are exploring a formal "Cost-Benefit Framework". This would help developers calculate exactly when adding another agent is "worth it" and when it's just a waste of money—helping make this technology affordable for everyday businesses, not just giant tech companies.
Conclusion:
Multi-agent AI is a powerful way to solve hard problems, but it requires careful management of team size (usually 3–4), debate length (usually 2–3 rounds), and specific roles to keep the AI from getting confused or overspending.



Comments